
Module 14 – Guided Lab: Hybrid Storage and Data Migration with AWS Storage Gateway File Gateway
Module 14 – Guided Lab: Hybrid Storage and Data Migration with AWS Storage Gateway File Gateway
Lab overview and objectives
In this lab, you will use the AWS Storage Gateway File Gateway service to attach a Network File System (NFS) mount to an on-premises data store. You will then replicate that data to an S3 bucket in AWS. Additionally, you will configure advanced Amazon S3 features, like Amazon S3 lifecycle policies and cross-Region replication.
After completing this lab, you should be able to:
- Configure a File Gateway with an NFS file share and attach it to a Linux instance
- Migrate a set of data from the Linux instance to an S3 bucket
- Create and configure a primary S3 bucket to migrate on-premises server data to AWS
- Create and configure a secondary S3 bucket to use for cross-Region replication
- Create an S3 lifecycle policy to automatically manage data in a bucket
Duration
This lab will require approximately 90 minutes to complete.
AWS service restrictions
In this lab environment, access to AWS services and service actions might be restricted to the ones that are needed to complete the lab instructions. You might encounter errors if you attempt to access other services or perform actions beyond the ones that are described in this lab.
Accessing the AWS Management Console
- At the top of these instructions, choose Start Lab to launch your lab.
A Start Lab panel opens, and it displays the lab status.
Tip: If you need more time to complete the lab, restart the timer for the environment by choosing the Start Lab button again. - Wait until the Start Lab panel displays the message Lab status: ready, then close the panel by choosing the X.
- At the top of these instructions, choose AWS.
This action opens the AWS Management Console in a new browser tab. The system automatically logs you in.
Tip: If a new browser tab does not open, a banner or icon is usually at the top of your browser with the message that your browser is preventing the site from opening pop-up windows. Choose the banner or icon, and then choose Allow pop-ups. - Arrange the AWS Management Console tab so that it displays alongside these instructions. Ideally, you will have both browser tabs open at the same time so that you can follow the lab steps more easily.
Do not change the Region unless specifically instructed to do so.
Task 1: Reviewing the lab architecture
This lab environment uses a total of three AWS Regions. A Linux EC2 instance that emulates an on-premises server is deployed to the us-east-1 (N. Virginia) Region. The Storage Gateway virtual appliance is deployed to the same Region as the Linux server. In a real-world scenario, the appliance would be deployed in a VMware vSphere or Microsoft Hyper-V environment, or as a physical Storage Gateway appliance.
The primary S3 bucket is created in the us-east-2 (Ohio) Region. Data from the Linux host is copied to the primary S3 bucket. This bucket can also be called the source.
The secondary S3 bucket is created in the us-west-2 (Oregon) Region. This secondary bucket is the target for the cross-Region replication policy. It can also be called the destination.
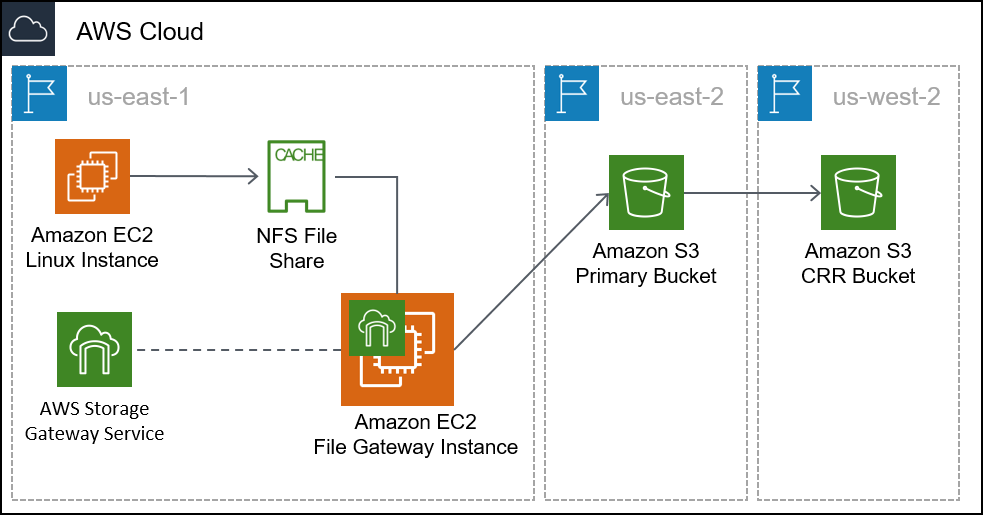
Task 2: Creating the primary and secondary S3 buckets
Before you configure the File Gateway, you must create the primary S3 bucket (or the source) where you will replicate the data. You will also create the secondary bucket (or the destination) that will be used for cross-Region replication.
- In the AWS Management Console, on the Services menu, select S3.
- Choose Create bucket then configure these settings:
- Bucket name: Create a name that you can remember easily. It must be globally unique.
- Region: US East (Ohio) us-east-2
- Bucket Versioning: Enable
For cross-Region replication, you must enable versioning for both the source and destination buckets.
- Choose Create bucket
- Repeat the previous steps in this task to create a second bucket with the following configuration:
- Bucket name: Create a name you can easily remember. It must be globally unique.
- Region: US West (Oregon) us-west-2
- Versioning: Enable
Task 3: Enabling cross-Region replication
Now that you created your two S3 buckets and enabled versioning on them, you can create a replication policy.
- Select the name of the source bucket that you created in the US East (Ohio) Region.
- Select the Management tab, under Replication rules select Create replication rule
- Configure the following for Replication rule configuration:
- Replication rule name: crr-full-bucket
- Status Enabled
- Choose a rule scope: This rule applies to all objects in the bucket
- Destination:
- Choose a bucket in this account
- Click Browse S3 and select the bucket you created in US West (Oregon) Region.
- Select Choose path
- IAM role: S3-CRR-Role
- Note: To find the AWS Identity and Access Management (IAM) role, in the search box, enter: S3-CRR (This role was pre-created with the required permissions for this lab)
- Choose Save
- Return to the bucket you created in the US East (Ohio) Region.
- Click Upload to upload a file from your local computer to the bucket.
For this lab, use a small file that does not contain sensitive information, such as a blank text file.
- Select Add files then click Upload
- Wait for the file to upload, then return to the bucket you created in the US West (Oregon) Region. The file that you uploaded should also be copied to this bucket.
Note: You may need to choose refresh the console for the object to appear.
Task 4: Configuring the File Gateway and creating an NFS file share
In this task, you will deploy the File Gateway appliance as an Amazon Elastic Compute Cloud (Amazon EC2) instance. You will then configure a cache disk, select an S3 bucket to synchronize your on-premises files to, and select an IAM policy to use. Finally, you will create an NFS file share on the File Gateway.
- At the top-left, choose the Services menu, then select Storage Gateway.
You can also search for Storage Gateway from the top of the Services menu to make locating it easier.
- At the top-right of the console, verify that the current Region is N. Virginia.
- Choose Create gateway
- Select Amazon S3 File gateway, then choose Next
- Select Amazon EC2, then choose the Launch instance button.
A new tab opens to the EC2 instance launch wizard. This link automatically selects the correct Amazon Machine Image (AMI) that must be used for the File Gateway appliance.
- Select the t2.xlarge instance type, then choose Next: Configure Instance Details
Note: t2.xlarge is the only instance type that you can select in this lab environment. If you select any other instance type, it will result in an error message at the end of the wizard.
The t2.xlarge instance type is used only as an example in this lab. For correct appliance sizing when you deploy a Storage Gateway appliance, refer to the Storage Gateway documentation.
- On the Configure instance details screen, configure these settings:
- Number of instances: 1
- Network: On-Prem-VPC
- Subnet: On-Prem-Subnet
- Auto-assign Public IP: Use subnet setting (Enable)
- Accept the default values for the remaining options
Note: You can ignore warning messages, such as: You do not have permissions to list instance profiles. Contact your administrator, or check your IAM permissions.
- Choose Next: Add Storage
- Choose Add New Volume and configure these settings:
- Volume Type: EBS
- Device: /dev/sdb
- Size (GiB): 150
- Volume Type: General Purpose SSD (gp2)
- Delete on Termination:
- Choose Next: Add Tags
- Choose Add Tag and configure these settings:
- Key: Name
- Value: File Gateway Appliance
- Instances:
- Volumes:
Note: Tags are case-sensitive.
- Choose Next: Configure Security Group
- Choose Select an existing security group, and then select:
- File Gateway activation and NFS access ports
- This security group is configured to allow traffic through ports 80 (HTTP), 443 (HTTPS), 53 (DNS), 123 (NTP), and 2049 (NFS). These ports enable the activation of the File Gateway appliance. They also enable connectivity from the Linux server to the NFS share that you will create on the File Gateway.
For additional information about the ports used by Storage Gateway, refer to the Storage Gateway documentation.
- This security group is configured to allow traffic through ports 80 (HTTP), 443 (HTTPS), 53 (DNS), 123 (NTP), and 2049 (NFS). These ports enable the activation of the File Gateway appliance. They also enable connectivity from the Linux server to the NFS share that you will create on the File Gateway.
- On-Prem SSH Access
- This security group is configured to allow Secure Shell (SSH) connections on port 22.

- Choose Review and Launch
Note: You will see warning messages at the top of the next screen. You can safely disregard these warnings for this lab. To prevent unwanted or malicious connections to your instances in a production environment, you should always create security groups that are as restrictive as possible. - Choose Launch
- On the Select an existing key pair or create a new key pair screen, configure these settings:
- Choose an existing key pair
- Select a key pair: Choose the available key
- I acknowledge that I have access to the selected private key file…
Note: This key pair is provided on the Details > Show > Credentials page for this lab.
- Choose Launch Instances
- Choose View Instances
Your File Gateway appliance instance should take a few minutes to deploy. - Monitor the status of the deployment and wait for Status Checks to complete.
Note: You might need to choose the refresh button within the AWS console. - Select your File Gateway instance from the list, then at the bottom of the screen, locate the IPv4 Public IP address and copy it. You will use this IP address when you complete the File Gateway deployment.
- Return to the AWS Storage Gateway tab in your browser. It should still be at the Select host platform screen.
- Verify that Amazon EC2 is selected, then choose Next
- For the Service endpoint, select Public, and then choose Next
- Paste the IPv4 Public IP address that you copied from your File Gateway Appliance instance, and then choose Next
- On the Activate gateway screen, configure these settings:
- Gateway time zone: GMT -5:00 Eastern Time (US & Canada)
- Gateway name: File Gateway
- Choose Activate gateway
- On the Configure local disks screen, wait for the Preparing local disks status to show that it finished processing (approximately 1 minute).
- After the processing is complete, go to Allocated to and select Cache.
- Select Save and continue
- On the Gateway health log group screen, select Disable logging.
- Select Save and continue
- Review then select Finish
- Wait for the File Gateway status to change to Running (approximately 1–2 minutes), then select the File Gateway entry and choose Create file share
- On the File share settings configuration screen, configure these settings:
- Gateway: Select the name of the File Gateway that you just created (which should be File Gateway)
- Amazon S3 bucket name: Enter the name of the source bucket that you created in the US East (Ohio) us-east-2 Region in Task 1.
- AWS Region: US East (Ohio) us-east-2
- Access objects using: Network File System (NFS)
- Choose Next
- On the Amazon S3 storage configuration screen, configure these settings:
- Storage class for new objects: S3 Standard
- Object metadata:
- Guess MIME type
- Give bucket owner full control
- Enable Requester Pays
- Access your S3 bucket: Use an existing IAM role
- IAM role: Paste the FgwIamPolicyARN, which you can retrieve by following these instructions –
- Choose the Details dropdown menu above these instructions
- Select Show
- Copy the FgwIamPolicyARN value
- Choose Next
Note: You might get a warning message that the file share is accessible from anywhere. For this lab, you can safely disregard this warning. In a production environment, you should always create policies that are as restrictive as possible to prevent unwanted or malicious connections to your instances. - Choose Next
- Review then select Create
- Monitor the status of the deployment and wait for Status to change to Available, which takes less than a minute.
Note: If you receive a user not authorized message at the top of the screen you can ignore this. This will not affect the lab. - Select the file share that you just created. At the bottom of the screen, note the command to mount the file share on Linux. You will need it for the next task.

Task 5: Mounting the file share to the Linux instance and migrating the data
Before you can migrate data to the NFS share that you created, you must first mount the share. In this task, you will mount the NFS share on a Linux server, then copy data to the share.
- Connect to the On-Prem Linux Server instance.
Microsoft Windows users
These instructions are specifically for Microsoft Windows users. If you are using macOS or Linux, skip to the next section.
- Above these instructions that you are currently reading, choose the Details dropdown menu, and then select Show
A Credentials window opens. - Choose the Download PPK button and save the labsuser.ppk file.
Note: Typically, your browser saves the file to the Downloads directory.
- Note the OnPremLinuxInstance address, if it is displayed.
- Exit the Details panel by choosing the X.
- To use SSH to access the EC2 instance, you must use PuTTY. If you do not have PuTTY installed on your computer, download PuTTY.
- Open putty.exe.
- To keep the PuTTY session open for a longer period of time, configure the PuTTY timeout:
- Choose Connection
- Seconds between keepalives: 30
- Configure your PuTTY session by using the following settings.
- Choose Session
- Host Name (or IP address): Paste the OnPremLinuxInstance for the instance you noted earlier
- Alternatively, return to the Amazon EC2 console and choose Instances
- Select the instance you want to connect to
- In the Description tab, copy the IPv4 Public IP value
- Back in PuTTY, in the Connection list, expand SSH
- Choose Auth (but don’t expand it)
- Choose Browse
- Browse to and select the labsuser.ppk file that you downloaded
- To select the file, choose Open
- Choose Open again
- To trust and connect to the host, choose Yes.
- When you are prompted with login as, enter: ec2-user
This action connects you to the EC2 instance. - Microsoft Windows users: Click here to skip ahead to the next task.
macOS and Linux Users
These instructions are specifically for macOS or Linux users. If you are a Windows user, skip ahead to the next task.
- Above these instructions that you are currently reading, choose the Details dropdown menu, and then select Show
A Credentials window opens. - Choose the Download PEM button and save the labsuser.pem file.
- Note the OnPremLinuxInstance address, if it is displayed.
- Exit the Details panel by choosing the X.
- Open a terminal window, and change directory to the directory where the labsuser.pem file was downloaded by using the cd command.
For example, if the labsuser.pem file was saved to your Downloads directory, run this command: - cd ~/Downloads
- Change the permissions on the key to be read-only, by running this command:
- chmod 400 labsuser.pem
- Run the following command (replace <public-ip> with the OnPremLinuxInstance address that you copied earlier).
- Alternatively, to find the IP address of the on-premises instance, return to the Amazon EC2 console and select Instances
- Select the instance that you want to connect to
- In the Description tab, copy the IPv4 Public IP value
ssh -i labsuser.pem ec2-user@<public-ip>
- When you are prompted to allow the first connection to this remote SSH server, enter yes.
Because you are using a key pair for authentication, you are not prompted for a password.
You should now be connected to the instance.
- On the Linux instance, to view the data that exists on this server, enter the following command:
ls /media/data
You should see 20 image files in the .png format.
- Create the directory that will be used to synchronize data with your S3 bucket by using the following command:
sudo mkdir -p /mnt/nfs/s3
- Mount the file share on the Linux instance by using the command that you copied at the end of the last task.
sudo mount -t nfs -o nolock,hard <File-Gateway-appliance-private-IP-address>:/<S3-bucket-name> /mnt/nfs/s3
For example:
sudo mount -t nfs -o nolock,hard 10.10.1.33:/lab-nfs-bucket /mnt/nfs/s3
- Verify that the share was mounted correctly by entering the following command:
df -h
The output of the command should be similar to the following example:
[ec2-user@ip-10-10-1-210 ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 483M 64K 483M 1% /dev
tmpfs 493M 0 493M 0% /dev/shm
/dev/xvda1 7.8G 1.1G 6.6G 14% /
10.10.1.33:/lab-nfs-bucket 8.0E 0 8.0E 0% /mnt/nfs/s3
- Now that you created the mount point, you can copy the data that you want to migrate to Amazon S3 into the share by using this command:
cp -v /media/data/*.png /mnt/nfs/s3
Task 6: Verifying that the data is migrated
You have finished configuring the gateway and copying data into the NFS share. Now, you will verify that the configuration works as intended.
- Choose the Services menu and select S3.
- Select the bucket that you created in the US East (Ohio) Region, and verify that the 20 image files are listed.
Note: You might need to choose the refresh in the AWS console.
- Return to the S3 buckets page and select the bucket that you created in the US West (Oregon) Region. Verify that the images files replicated to this bucket, based on the policy that you created earlier.
Note: S3 Object replication can take up to 15 minutes to complete. Keep refreshing until you see the replicated objects.
You successfully migrated data to Amazon S3 by using AWS Storage Gateway in File Gateway mode! After your data is stored in Amazon S3, you can act on it like native Amazon S3 data. In this lab, you created a replication policy to copy the data to a secondary Region. You could also perform other operations, such as configuring a lifecycle policy. For example, you could migrate infrequently used data automatically from S3 Standard to Amazon Simple Storage Service Glacier for long-term storage, which can reduce costs.
Submitting your work
- At the top of these instructions, choose Submit to record your progress and when prompted, choose Yes.
- If the results don’t display after a couple of minutes, return to the top of these instructions and choose Grades
Tip: You can submit your work multiple times. After you change your work, choose Submit again. Your last submission is what will be recorded for this lab. - To find detailed feedback on your work, choose Details followed by View Submission Report.
Lab complete
Congratulations! You have completed the lab.
- Choose End Lab at the top of this page, and then select Yes to confirm that you want to end the lab.
A panel should appear with this message: DELETE has been initiated… You may close this message box now. - Select the X in the top right corner to close the panel.




